-Make a personal Japanese tutor in a few minutes
This is an article by Chase Zhang, Twitter @ant_sz
Over the past year, Large Language Models (LLMs) have seen burgeoning growth and development. As a data systems enthusiast, it’s essential to explore and study this hot field to stay updated. This article summarizes my recent experience in developing LLM applications using flows.network under Rust.
Concepts around Large Language Models
When talking about LLMs, ChatGPT and OpenAI immediately come to mind. Despite OpenAI's recent change in CEO, their significant role in advancing and promoting LLMs is undeniable. From the perspective of individual developers and small companies, training and deploying LLMs is impractical. As a data system developer, I prefer to represent the concept of LLMs as follows:
Concept of LLM
From an application developer's perspective, LLMs can be viewed as functions composed of massive training data. Since this function is static, it requires Prompts and Context as inputs during use. The function's role is to generate outputs most likely to meet user needs based on the Prompt and Context. This output, together with the user’s input (Chat), is fed back into the LLM as new Context.
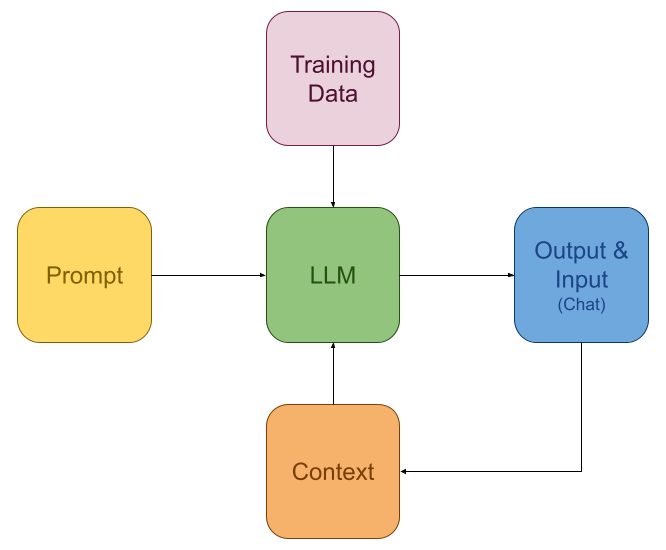 This mindset allows LLM developers to focus less on the internal details of LLMs and more on preparing inputs for this “function.” Of course, there are nuances in prompt-tuning, but today's LLMs are remarkably “smart” and often produce effective results with simple prompts.
This mindset allows LLM developers to focus less on the internal details of LLMs and more on preparing inputs for this “function.” Of course, there are nuances in prompt-tuning, but today's LLMs are remarkably “smart” and often produce effective results with simple prompts.
RAG and Vector Store
RAG (Retrieval Augmented Generation) and Vector Store are essential in LLM applications. RAG, a term that emerged with the rise of LLMs, addresses the challenge of LLMs in quickly utilizing new knowledge. For example, ChatGPT has long been limited to answering questions based on pre-2021 knowledge. While Fine-tuning can solve this, it's a costly and slow process.
Initially, RAG utilized Vector Stores for information extraction, primarily in Q&A systems. Traditional keyword-based query systems often fail to return relevant results for natural language queries. Thus, Vector Stores, combined with a language model, compute Embeddings (vector data). These stores then use similarity calculations to extract relevant information as Context for LLMs. The traditional Vector Store-based RAG process is depicted below:
Usage of Vector Store
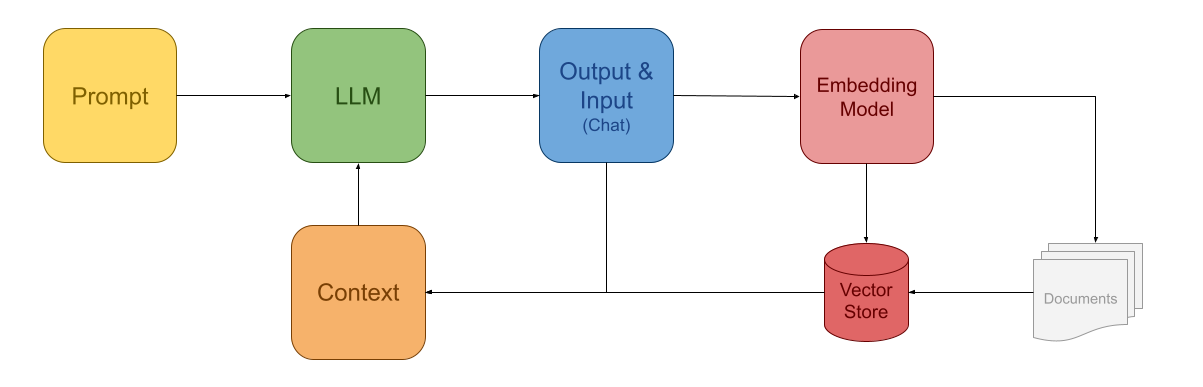 In this framework, the Embedding Model converts both user queries and existing documents into vectors within the same metric space, ensuring similarity. When calling the LLM, the extracted information serves as Context, allowing the LLM to answer various questions, including those on newly added documents. However, this framework’s capability can sometimes be limited by the performance of the Embedding Model.
In this framework, the Embedding Model converts both user queries and existing documents into vectors within the same metric space, ensuring similarity. When calling the LLM, the extracted information serves as Context, allowing the LLM to answer various questions, including those on newly added documents. However, this framework’s capability can sometimes be limited by the performance of the Embedding Model.
RAG and Assistant
A more powerful RAG framework, based on the so-called Assistant model, has recently gained popularity. The Assistant acts as a third agent-like role in the interaction between the LLM and the user, similar to a chatbot. It can accept commands output by the LLM, execute queries, and return results as Context. This model is illustrated below:
Assistant Framework
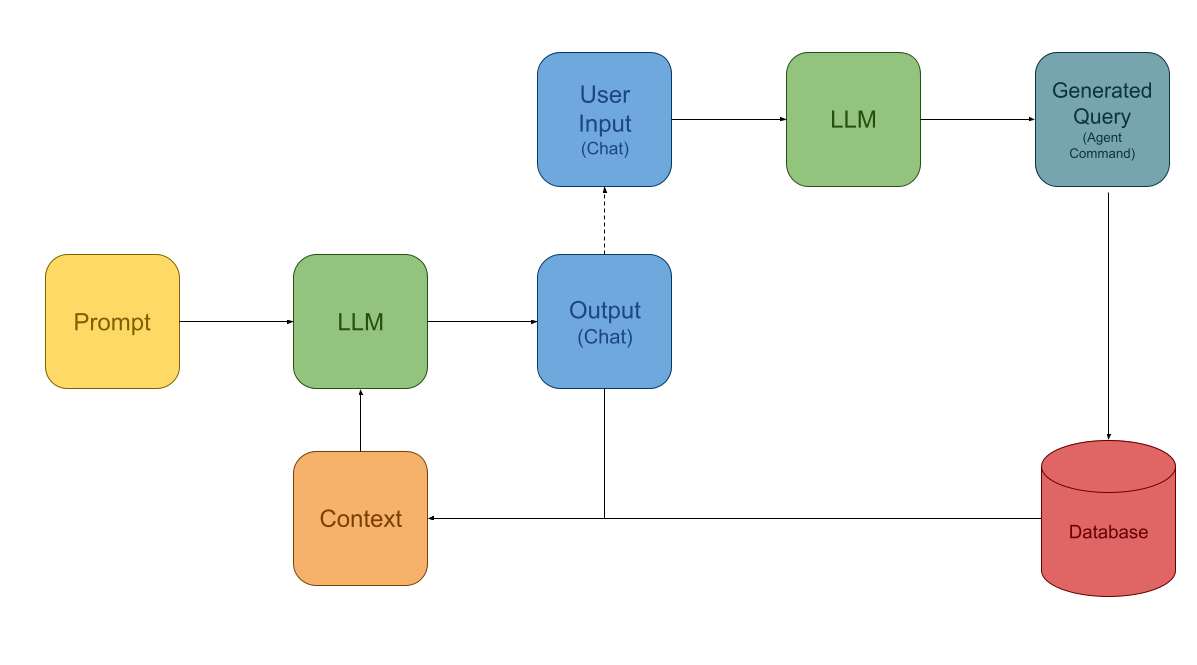 This model is based on a simple yet effective idea: LLMs are powerful enough to translate user questions into formatted statements, such as SQL or JSON-described function calls. If LLMs first output commands they believe can retrieve data, and an Agent executes these queries and returns the results to the current session’s Context, the LLM can access the latest information. This flexible approach allows querying traditional databases without pre-processing with an Embedding model. Moreover, LLMs can conduct multiple rounds of queries before returning results, making this a highly powerful framework.
This model is based on a simple yet effective idea: LLMs are powerful enough to translate user questions into formatted statements, such as SQL or JSON-described function calls. If LLMs first output commands they believe can retrieve data, and an Agent executes these queries and returns the results to the current session’s Context, the LLM can access the latest information. This flexible approach allows querying traditional databases without pre-processing with an Embedding model. Moreover, LLMs can conduct multiple rounds of queries before returning results, making this a highly powerful framework.
Additionally, the Assistant framework can control external systems, not just data queries, significantly expanding the potential applications of LLMs.
Development of LLM Applications
As average developers, we might feel powerless regarding significant framework developments in LLMs. However, we can still build useful tools using available resources. Currently, the most popular LLM framework is perhaps LangChain. Essentially, these tools are workflow management tools that allow users to weave their application logic into executable workflows.
Here, I chose flows.network, a Rust-implemented serverless LLM workflow platform, to develop a Telegram GPT application. It offers various callable methods and tools to help outline your LLM application flow. Your application is compiled into WebAssembly and runs on the hosted platform provided by Flows.Network, which is currently free.
Flows.Network Supported Integrations
The above image shows the integrations provided by Flows.Network. These interfaces are implemented as APIs with callable Rust SDKs. Users need only focus on organizing application logic and calling these methods. One reason for choosing this over LangChain is its lightweight framework, which avoids widely complained heavy abstractions in LangChain.
I used Flows.Network to create a Telegram Bot for Q&A and learning Japanese, which you can find at https://github.com/shanzi/Telegram-ChatGPT. The Bot supports simple commands and maintains conversation context with Reply-To:!
Q&A Mode
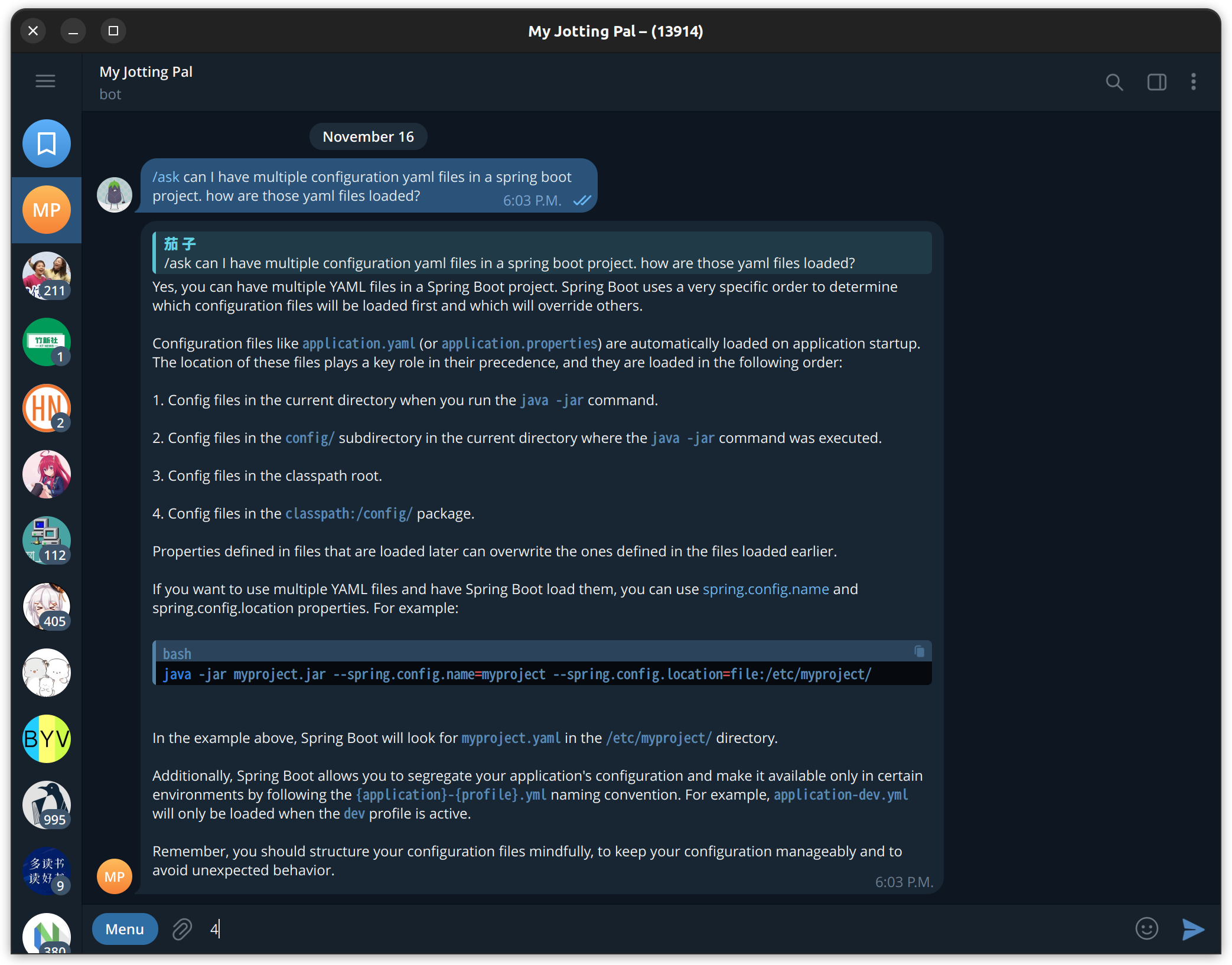 Japanese Learning Mode
Screenshot from 2023-11-18 17-35-12
Notably, to handle Telegram’s peculiar Markdown syntax, I wrote a parser using Nom to process and escape Markdown syntax in ChatGPT’s output. See the src/markdown.rs file for details.
Japanese Learning Mode
Screenshot from 2023-11-18 17-35-12
Notably, to handle Telegram’s peculiar Markdown syntax, I wrote a parser using Nom to process and escape Markdown syntax in ChatGPT’s output. See the src/markdown.rs file for details.
Currently, Flows.Network requires WebAssembly for building, which hinders local execution and debugging. This can be a drawback, but proper configuration allows automatic build and deployment upon pushing to your GitHub repository, providing a convenient writing experience, which compensate for this drawback.
Conclusion
This article introduced general concepts of LLM applications and shared my experience using Flows.Network to develop an LLM application. I personally enjoy writing LLM applications in Rust, and Flows offers needed APIs, freeing me from dealing with various interfaces. The convenience of deploying FaaS with Wasm is also commendable. I hope to see more platforms like this emerge to facilitate the development of diverse GPT applications.
Feel free to Fork and try out my Telegram Bot: https://github.com/shanzi/Telegram-ChatGPT